Kaplan Meier Survival Curves
Introduction to Kaplan-Meier Method
From the pervious chapter, we learned that the data layout that we typically use for survival analysis is given by the table shown here:
| Ordered failure times | # of failures | # censored in | Risk set R |
|---|---|---|---|
| . | . | . | . |
| . | . | . | . |
| . | . | . | . |
This layout is the basis upon which Kaplan-Meier survival curves are derived. The first column represents ordered survival times from smallest to largest. The second column represents frequency counts for failures at each distinct failure time. The third one represents frequency counts of those persons censored in the time interval from failure time up to but not including the next failure time . The last column gives the risk set, which denotes the collection of individuals who have survived at least to time .
An Example of Kaplan-Meier Curves
Let's still take a look at the dataset from the last chapter:

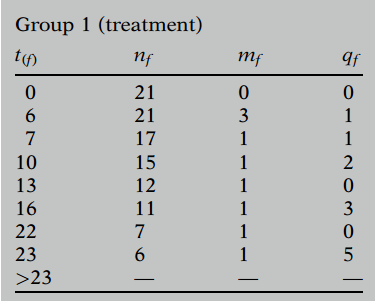
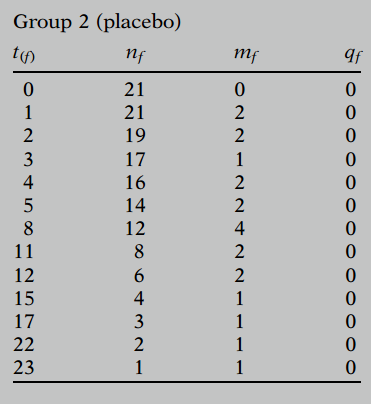
We list these data as the KM table:
| Group 1 | Group 2 |
|---|---|
 |  |
Each table begins with a survival time of zero, even though no subject actually failed at the start of follow-up. The reason for the zero is to allow for the possibility that some subjects might have been censored before the earliest failure time.
We also have each table contain a column denoted as that gives the number of subjects in the risk set at the start of the interval. counts subjects at risk for failing instantaneously prior to time .
Now let's talk about how to compute the KM curve for group 2.
For group 2, because we don't have any censored subjects, the computation of the KM curve is straightforward.
| 0 | 21 | 0 | 0 | 1 |
| 1 | 21 | 2 | 0 | 19/21=0.90 |
| 2 | 19 | 2 | 0 | 17/21=0.81 |
| 3 | 17 | 1 | 0 | 16/21=0.76 |
| 4 | 16 | 2 | 0 | 14/21=0.67 |
| 5 | 14 | 2 | 0 | 12/21=0.57 |
| 8 | 12 | 4 | 0 | 8/21=0.38 |
| 11 | 8 | 2 | 0 | 6/21=0.29 |
| 12 | 6 | 2 | 0 | 4/21=0.19 |
| 15 | 4 | 1 | 0 | 3/21=0.14 |
| 17 | 3 | 1 | 0 | 2/21=0.10 |
| 22 | 2 | 1 | 0 | 1/21=0.05 |
| 23 | 1 | 1 | 0 | 0/21=0.00 |
Here, is the survival probability at time . The probability of surviving past the first ordered failure time of week is given by or because people failed at week, so that people from the original remain as survivors past week. Similarly, the next probability concerns subjects surviving past weeks, which is or because subjects failed at week and subjects failed at weeks leaving out of the original subjects surviving past weeks.
Recall that no subject in group 2 was censored, so the column for group 2 consists entirely of zeros. If some of the q's had been nonzero, an alternative formula for computing survival probabilities would be needed. This alternative formula is called the Kaplan-Meier (KM) approach and can be illustrated using the group 2 data even though all values of are zero.
For instance, an alternative way to calculate the survival probability of exceeding weeks for the group 2 data can be written using the KM formula shown here. This formula involves the product of conditional probability terms. That is, each term in the product is the probability of exceeding a specific ordered failure time given that a subject survives up to that failure time. We have:
Thus, in the KM formula for survival past weeks, the term gives the probability of surviving past the first ordered failure time, week, given survival up to the first week. Note that all persons in group 2 survived up to week, but that failed at week, leaving persons surviving past week.
Similarly, the term gives the probability of surviving past the third ordered failure time at week , given survival up to week . There were persons who survived up to week and of these then failed, leaving survivors past week . Note that the persons in the denominator represents the number in the risk set at week .
Notice that the product terms in the KM formula for surviving past weeks stop at the 4th week with the component . Similarly, the KM formula for surviving past weeks stops at the eighth week:
Generally speaking, KM formula for a survival probability is limited to product terms up to the survival week being specified. Thus, KM formula is often called "product-limit" formula.
Now let's consider the KM formula for group 1 data.
| 0 | 21 | 0 | 0 | |
| 6 | 21 | 3 | 1 | |
| 7 | 17 | 1 | 1 | |
| 10 | 15 | 1 | 2 | |
| 13 | 12 | 1 | 0 | |
| 16 | 11 | 1 | 3 | |
| 22 | 7 | 4 | 0 | |
| 23 | 6 | 2 | 5 |
The other survival estimatesb are calculated by multiplying the estimate for the immediately preceding failure time by a fraction. For example, the fraction is for surviving past week , because subjects remain up to week and of these subjects fail to survive past week . The fraction is for surviving past week , because people remain up to week and of these fails to survive past week . The other fractions are calculated similarly.
Plots of the KM curves for groups 1 and 2 are shown here on the same graph. Notice that the KM curve for group 1 is consistently higher than the KM curve for group 2. These figures indicate that group 1, which is the treatment group, has better survival prognosis than group 2, the placebo group.
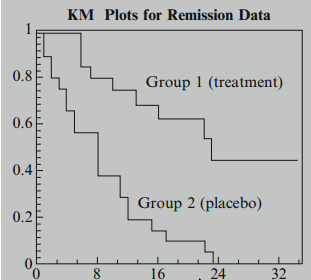
Note that we can obtain KM plots from R using the "survival" package.
General Features of KM Curves
General KM Formula
For example, the probability of surviving past weeks is given in the table for group 1 by times , which equals . But the can be alternatively written as the product of the fractions and . Thus, the product limit formula for surviving past weeks is given by the triple product shown here.